
Claude Code vs Codex CLI
Comparing their approaches and sharing my preferences. With a special appearance by two others.

Despite not being someone who enjoys using the terminal that much, Claude Code’s became a core part of my developer stack since late May this year. I’d tried it in the past and been disappointed, but Claude 4.0+ had clearly resulted in a step-change in reliability and performance.
When GPT-5 launched and was integrated into Codex CLI, I was eager to see if OpenAI could match the performance of Claude Code. A lot of people on Twitter clearly thought it did. Additionally, I was curious about the architectural choices in Codex, specifically on the tooling front. While the models are of course the key elements, I believe the tooling and the post-training to use the tools can play a significant role in the actual developer experience.
Tooling comparison
Claude Code has access to numerous tools, and that’s even before we get to MCPs, custom sub-agents, etc:
File operations: read, write, edit, multi-edit, glob, grep
Command execution: Bash, Bash output, KillShell
Network: search and fetch
Task management: Task (create subagents to do a specific task), TodoWrite, ExitPlanMode
Jupyter: notebook edits specific to python notebooks
A number of these tasks could be done via the shell directly, but Anthropic’s created dedicated tools that enforce certain rules and/or improve performance over standard shell commands. For example, the Edit and MultiEdit tools enforce reading the files first before making any changes. The latter also requires all edits to be successfully made before saving the file – if any edit fails, the entire set of changes are undone.
Codex’s approach is very minimal – it only has access to three tools:
shell
update_plan
view_image
They’ve effectively taken the approach of attempting everything through pure shell commands. There are no multiple sub-agents that are given specific tasks to work on, nor enforcement of rules such as “read before writing”, etc. It demonstrates pure trust in the model, with a larger context window, being able to figure things out as needed through one long conversation.
A detailed breakdown of the tools and their documentation is at the end if you’re curious.
My experience
First and foremost, it’s important for me to call out that both these products (and other coding agents like Devin and Cursor’s Agent) are genuinely incredible. I can write code, but I haven’t professionally done so for ~10 years and would not have been able to build what I have without them. To me they all are somewhat substitutable – if you took any one of them away, I’d probably make do with an alternative.
Having said that, I do have some preferences based on the task at hand. These tasks are on a fairly mature project at this stage:
Feature implementation: Claude Code, with Sonnet, remains my go-to. I’ve generally found it to handle fairly complex requests (usually full feature implementations) given a spec really well. I haven’t had much success (defined as near-complete implementation) with Codex CLI yet. This despite encouraging Codex to create plan.md files with detailed requirements for each phase. My thesis is the tooling/sub-agent approach from Claude is what makes the difference here – I love that Codex is trying something different in just trusting the model, but I do wonder if there’s context rot that ultimately causes issues
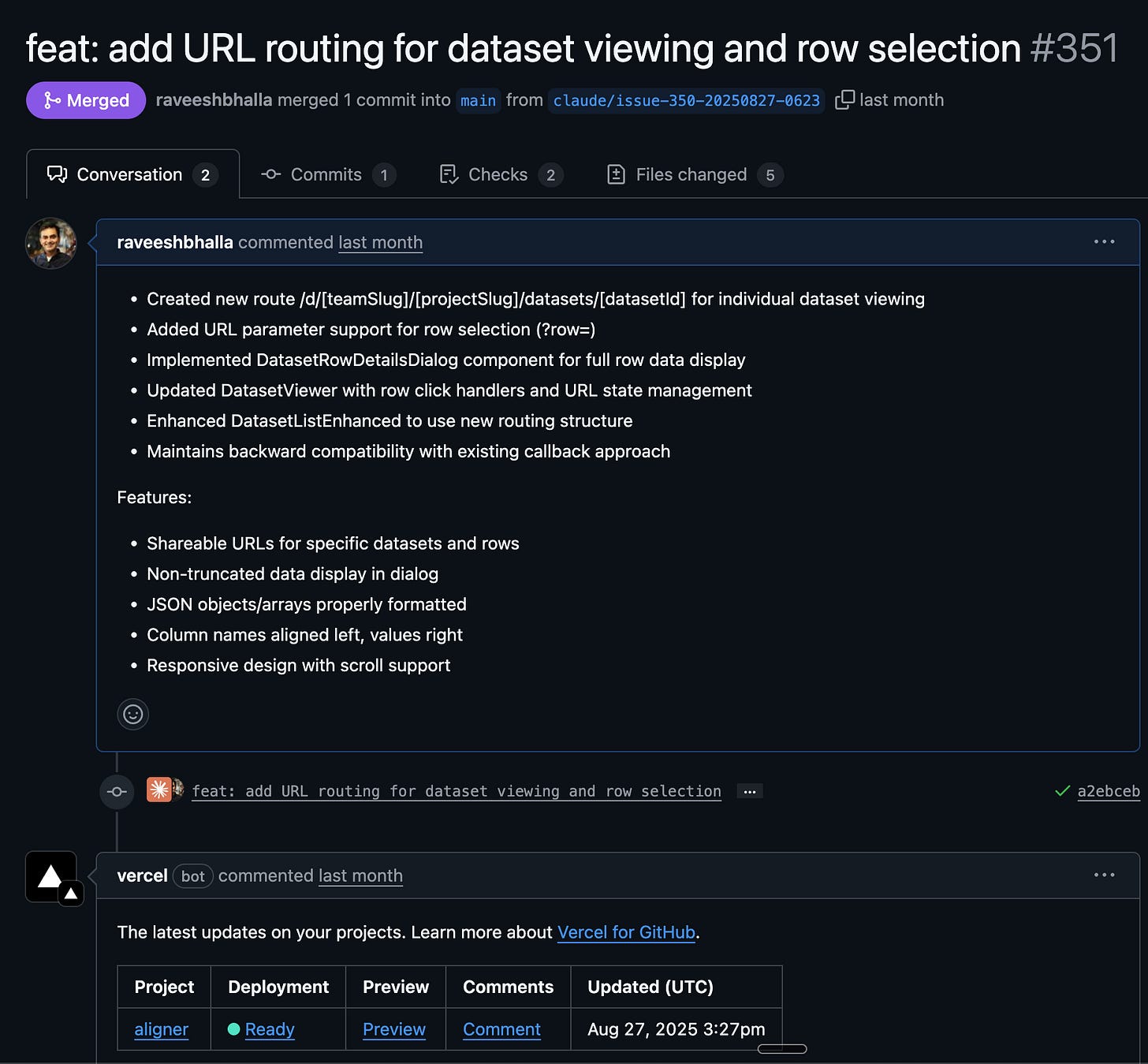
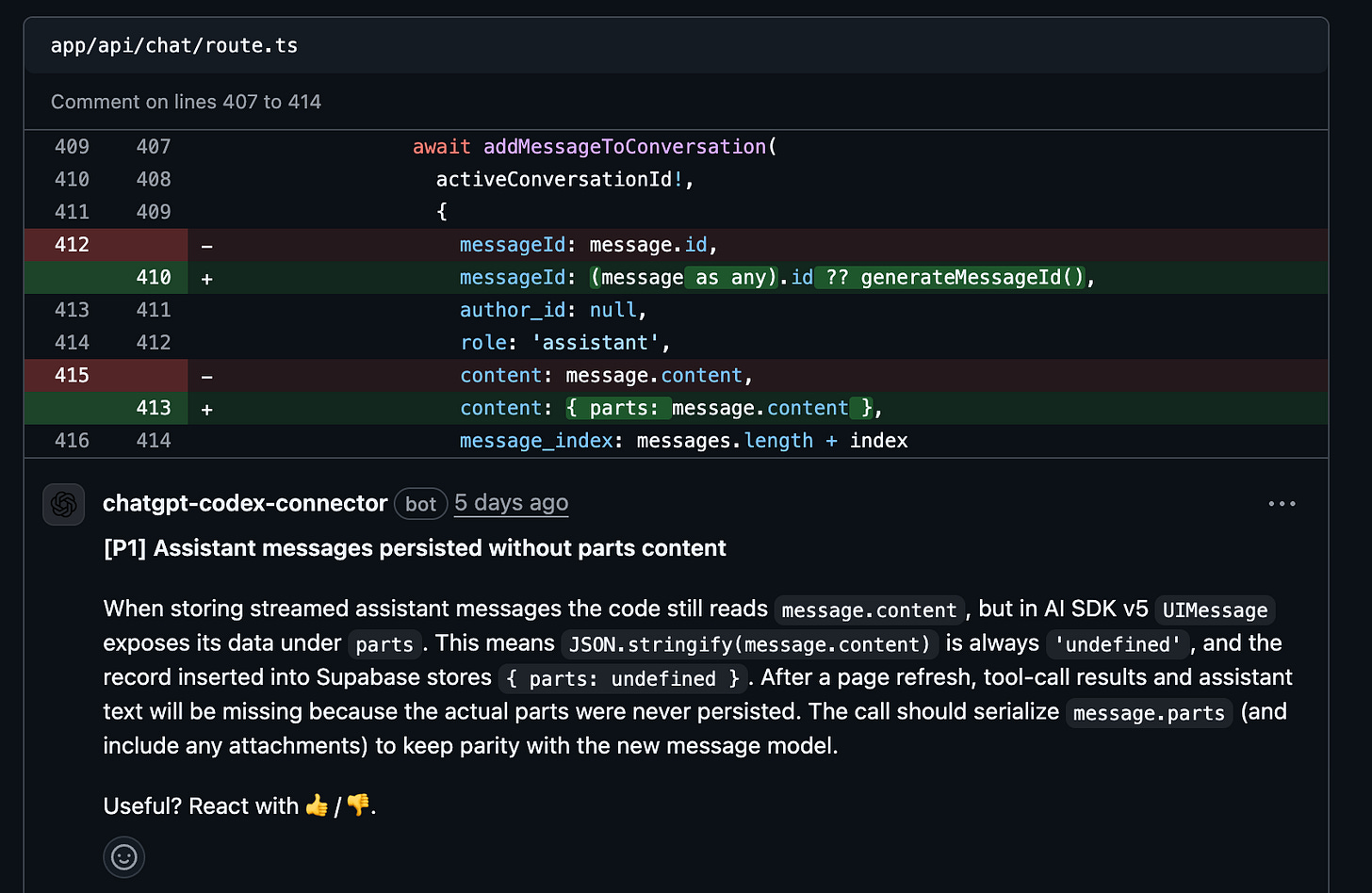
Code reviews and debugging: I actually really like Codex here. On numerous occasions it has done a better job identifying the root cause of issues across multiple modules. It also does a better job with code reviews, both if you ask it to locally as well as in GitHub. In the latter, I also like how it drops comments on specific lines (like a human PR reviewer!) versus one large blob of text from Claude Code. Also, it kinda helps that the personality is neutral and not over excited.
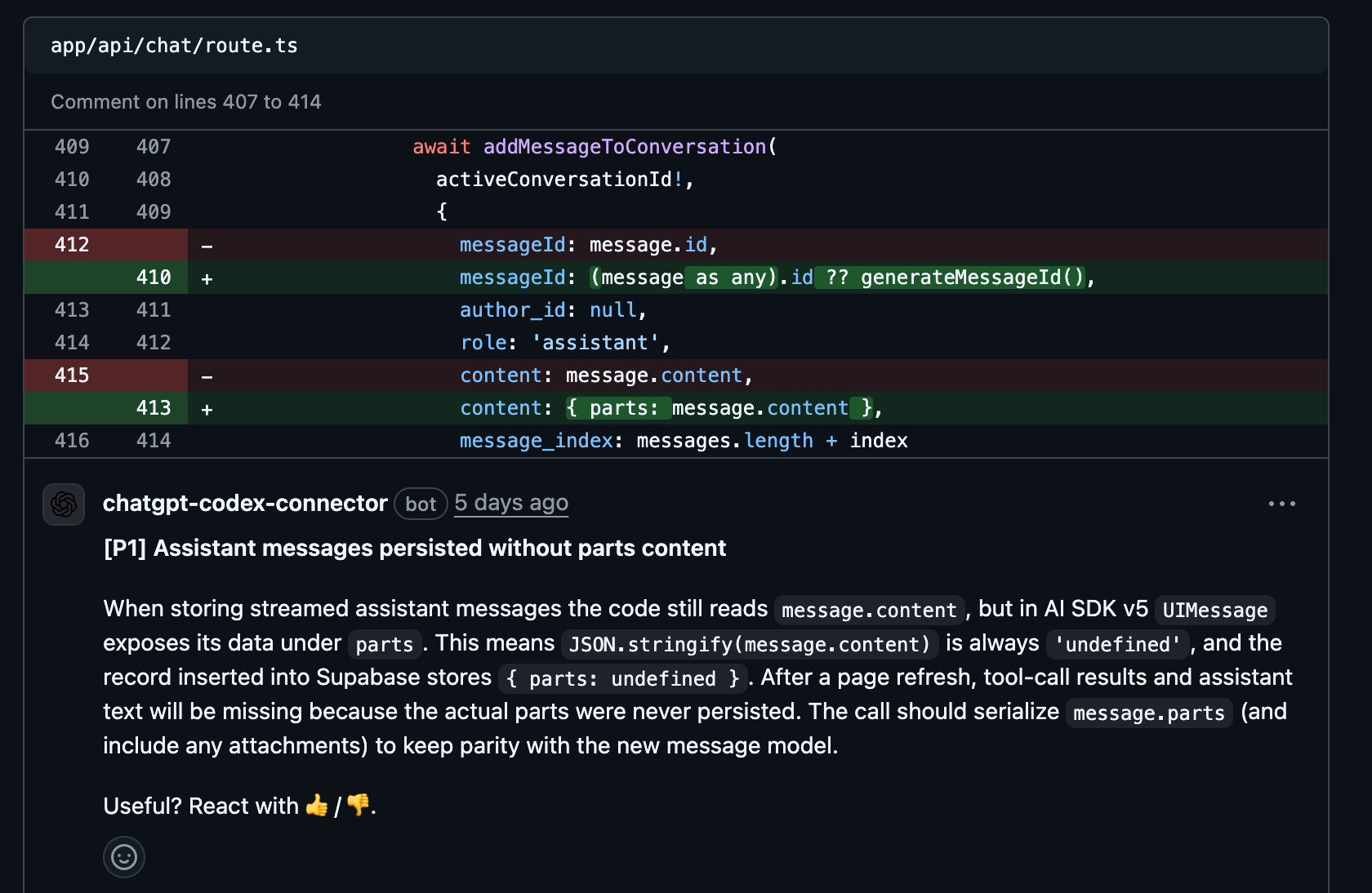
Documentation: this is where Devin shines, and I honestly think Cognition is slept on. DeepWiki is a great product, and the details Devin provides in pull requests are unmatched (screenshot below). This overall makes Devin the closest to a human coder.

IDE: The use case for IDEs for me is the final stretch of any initiative plus debugging. I’m hopeful about Windsurf post the Cognition acquisition but the tab model in Cursor remains the best I’ve seen.

Appendix
Claude Code
File Operations
Read
Purpose: Read files from the local filesystem
Parameters:
- file_path (required): Absolute path to the file
- offset (optional): Line number to start reading from
- limit (optional): Number of lines to read
Features:
- Reads up to 2000 lines by default
- Supports images (PNG, JPG, etc.) - displays visually
- Supports PDFs - processes page by page
- Supports Jupyter notebooks (.ipynb) - shows all cells with outputs
- Returns content with line numbers (cat -n format)
- Truncates lines longer than 2000 characters
Write
Purpose: Write content to files, overwriting existing content
Parameters:
- file_path (required): Absolute path to the file
- content (required): Content to write
Important Notes:
- Must use Read tool first if editing existing files
- Overwrites existing files completely
- Prefer editing over writing new files
Edit
Purpose: Perform exact string replacements in files
Parameters:
- file_path (required): Absolute path to the file
- old_string (required): Exact text to replace
- new_string (required): Replacement text
- replace_all (optional): Replace all occurrences (default: false)
Requirements:
- Must use Read tool first
- old_string must be unique in file (unless using replace_all)
- Preserve exact indentation from Read output
- Never include line number prefixes in strings
MultiEdit
Purpose: Make multiple edits to a single file in one operation
Parameters:
- file_path (required): Absolute path to the file
- edits (required): Array of edit operations
Edit Object Structure:
- old_string (required): Text to replace
- new_string (required): Replacement text
- replace_all (optional): Replace all occurrences
Features:
- Edits applied sequentially in order
- All edits must succeed or none are applied (atomic)
- More efficient than multiple Edit calls
Glob
Purpose: Fast file pattern matching using glob patterns
Parameters:
- pattern (required): Glob pattern (e.g., "/*.js", "src//*.ts")
- path (optional): Directory to search in (defaults to current)
Features:
- Works with any codebase size
- Returns paths sorted by modification time
- Supports standard glob patterns
- Use for finding files by name patterns
Grep
Purpose: Powerful search tool built on ripgrep
Parameters:
- pattern (required): Regular expression pattern
- path (optional): File or directory to search
- glob (optional): File pattern filter (e.g., "*.js")
- type (optional): File type filter (e.g., "js", "py")
- output_mode (optional): "content", "files_with_matches", "count"
- -i (optional): Case insensitive search
- -n (optional): Show line numbers (content mode only)
- -A/-B/-C (optional): Context lines after/before/around matches
- multiline (optional): Enable multiline matching
- head_limit (optional): Limit output to first N results
Output Modes:
- files_with_matches: Just file paths (default)
- content: Shows matching lines with context
- count: Shows match counts per file
Command Execution
Bash
Purpose: Execute bash commands in persistent shell
Parameters:
- command (required): Bash command to execute
- description (optional): 5-10 word description of what command does
- timeout (optional): Timeout in milliseconds (max 600000)
- run_in_background (optional): Run command in background
Important Guidelines:
- Quote file paths with spaces: "path with spaces"
- Use ; or && to separate multiple commands
- Avoid cd - use absolute paths instead
- NEVER use find, grep, cat, head, tail - use dedicated tools
- Use rg (ripgrep) if you must grep
- Commands timeout after 2 minutes by default
Git Operations:
- For commits: Use HEREDOC format for commit messages
- Always include Claude attribution in commits
- Never use -i flag (interactive mode not supported)
- Check git status/diff before committing
BashOutput
Purpose: Retrieve output from background bash processes
Parameters:
- bash_id (required): ID of background shell
- filter (optional): Regex to filter output lines
Usage:
- Monitor long-running background processes
- Only shows new output since last check
- Returns stdout, stderr, and shell status
KillShell
Purpose: Terminate background bash processes
Parameters:
- shell_id (required): ID of shell to kill
Web & Search
WebFetch
Purpose: Fetch and analyze web content using AI
Parameters:
- url (required): Valid URL to fetch
- prompt (required): What information to extract
Features:
- Converts HTML to markdown
- 15-minute cache for repeated requests
- Handles redirects (will inform you of redirect URLs)
- HTTP URLs automatically upgraded to HTTPS
- Content may be summarized if very large
WebSearch
Purpose: Search the web for current information
Parameters:
- query (required): Search query (min 2 characters)
- allowed_domains (optional): Only include these domains
- blocked_domains (optional): Exclude these domains
Notes:
- Only available in US
- Use for information beyond knowledge cutoff
- Account for current date when searching
Task Management
Task
Purpose: Launch specialized agents for complex tasks
Parameters:
- description (required): 3-5 word task description
- prompt (required): Detailed task description
- subagent_type (required): Type of agent to use
Available Agent Types:
- general-purpose: Complex research, code search, multi-step tasks
- statusline-setup: Configure Claude Code status line
- output-style-setup: Create Claude Code output styles
When to Use:
- Open-ended searches requiring multiple rounds
- Complex multi-step tasks
- When you need specialized capabilities
When NOT to Use:
- Reading specific file paths (use Read/Glob)
- Searching specific class definitions (use Glob)
- Searching within 2-3 known files (use Read)
TodoWrite
Purpose: Create and manage structured task lists
Parameters:
- todos (required): Array of todo objects
Todo Object Structure:
- content (required): Imperative description ("Run tests")
- activeForm (required): Present continuous form ("Running tests")
- status (required): "pending", "in_progress", "completed"
Usage Guidelines:
- Use for complex multi-step tasks (3+ steps)
- Only ONE task should be in_progress at a time
- Mark tasks completed immediately after finishing
- Update status in real-time
- Remove irrelevant tasks entirely
When to Use:
- Complex multi-step tasks
- Non-trivial implementations
- User requests multiple tasks
- User explicitly asks for todo list
When NOT to Use:
- Single straightforward tasks
- Trivial tasks completable in <3 steps
- Purely conversational requests
ExitPlanMode
Purpose: Exit planning mode after creating implementation plan
Parameters:
- plan (required): Concise implementation plan (markdown supported)
Usage:
- Only use when task requires planning implementation steps
- NOT for research tasks or understanding codebase
- Use after finishing planning, before coding
Jupyter Notebooks
NotebookEdit
Purpose: Edit Jupyter notebook cells
Parameters:
- notebook_path (required): Absolute path to .ipynb file
- new_source (required): New cell content
- cell_id (optional): ID of cell to edit
- cell_type (optional): "code" or "markdown"
- edit_mode (optional): "replace", "insert", "delete"
Edit Modes:
- replace: Replace existing cell content (default)
- insert: Add new cell at specified position
- delete: Remove cell at specified position
Notes:
- Cell numbering is 0-indexed
- When inserting, new cell appears after specified cell_id
- cell_type required when using insert modeCodex CLI
shell - Required: command (string array—think ["bash","-lc","echo hi"]) - Optional: workdir (path to run in; always set it), timeout_ms (int), with_escalated_permissions (bool for running outside sandbox), justification (one-sentence reason when escalating) update_plan - Optional: explanation (string) - Required: plan (array of steps, each with step text and status set to pending, in_progress, or completed) view_image - Required: path (string path to a local image file to attach)
The context rot observation is bang on. I've noticed the same thing when sessions drag on. The fix I've found is being really deliberate with AGENTS.md rules and breaking tasks into smaller chunks. Codex's cascading config system actually handles this better than most people realise. Wrote up the full mechanics of how it works: https://reading.sh/the-definitive-guide-to-codex-cli-from-first-install-to-production-workflows-a9f1e7c887ab
Great write-up Raveesh - as you say you can somewhat adjust to the trade offs of the different approaches - have you noticed how sensitive each tool is to truncating the context window for larger legacy codebases - and which degrades most gracefully?